The Most In-demand Categories In UK For Girls Clothing: Insights From Woven Insights


Understanding market trends in the fashion industry is crucial for brands and retailers looking to stay ahead of consumer preferences. In UK, the demand for girls' clothing is shaped by factors such as seasonal trends, cultural influences, and emerging styles. By leveraging data-driven insights, businesses can better align their offerings with consumer needs. In 2025, the global children's apparel market is expected to witness steady growth, with a strong demand for girls' fashion across various regions.
The Most In-Demand 2024 Girl Clothing Categories In the UK
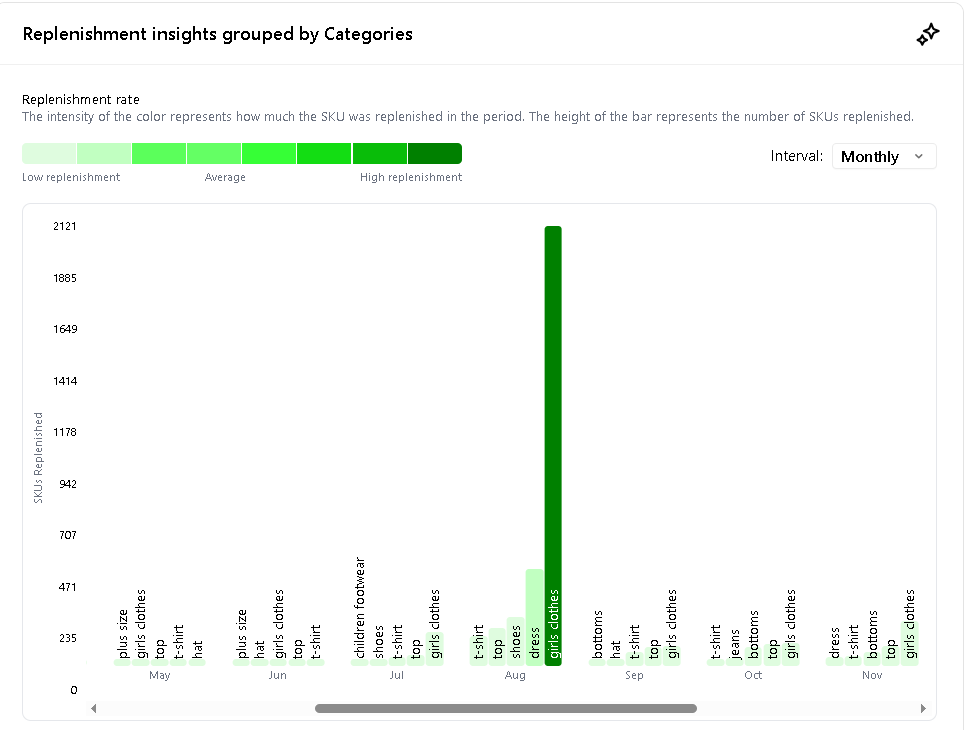
Using Woven Insights' Market Insights module, we can pinpoint the most in-demand boys clothing categories through our Replenishment Analysis feature. This feature tracks how quickly products are restocked after selling out, providing a clear indicator of demand.
From January to December 2024, the top girls' clothing categories with the highest replenishment rates were:
1. Girls clothes
2. Top
3. T-shirt
4. Bottoms
How to Leverage These Insights
For brands and retailers looking to enhance their market presence in the girls' clothing segment, leveraging insights from Woven Insights can be highly beneficial. Here’s how:
- Optimize Product Assortments: Understanding which categories such as dresses, athleisure, or sustainable clothing are in high demand allows businesses to stock the right mix of products.
- Refine Pricing Strategies: Competitive pricing analysis helps brands position their products effectively, whether targeting budget-conscious buyers or premium shoppers.
- Enhance Marketing Campaigns: Knowing the trending styles enables brands to create targeted marketing campaigns that resonate with their audience.
- Improve Inventory Management: Forecasting demand for specific categories minimizes overstocking or stock-outs, leading to better operational efficiency.
- Adapt to Regional Preferences: Fashion trends can vary by location, and tapping into region-specific data helps brands tailor their offerings accordingly.
Conclusion
Staying ahead in the competitive girls' clothing market in UK requires a keen understanding of emerging trends and consumer preferences. By leveraging the insights provided by Woven Insights, brands and retailers can make data-driven decisions that enhance their product offerings, marketing strategies, and overall business performance. Investing in market intelligence ensures that businesses remain agile and responsive to the ever-evolving demands of young fashion consumers.
About Woven Insights
Woven Insights is a comprehensive market analytics solution that provides fashion brands with real-time access to retail market and consumer insights, sourced from over 70 million real shoppers and 20 million analyzed fashion products. Our platform helps brands track market trends, assess competitor performance, and refine product strategies with precision.
Woven Insights provides you with all the actionable data you need to create fashion products that are truly market-ready and consumer-aligned.
Click on the Book a demo button below to get started today.
